GPU vs CPU Deep Learning: Training Performance of Convolutional Networks
In the technology community, especially in IT, many of us are searching for knowledge and how to develop our skills. After researching Deep Learning through books, videos, and online articles, I decided that the natural next step was to gain hands-on experience.
I started with Venkatesh’s tutorial of building an image classification model using a Convolution Neural Network (CNN) to classify cat and dog images. The “cat and dog image classification” issue is considered by some to be a “Hello World” style example for convolutional and Deep Learning networks. However, with Deep Learning, there is a lot more involved than simply displaying the “Hello World” text using a programming language.
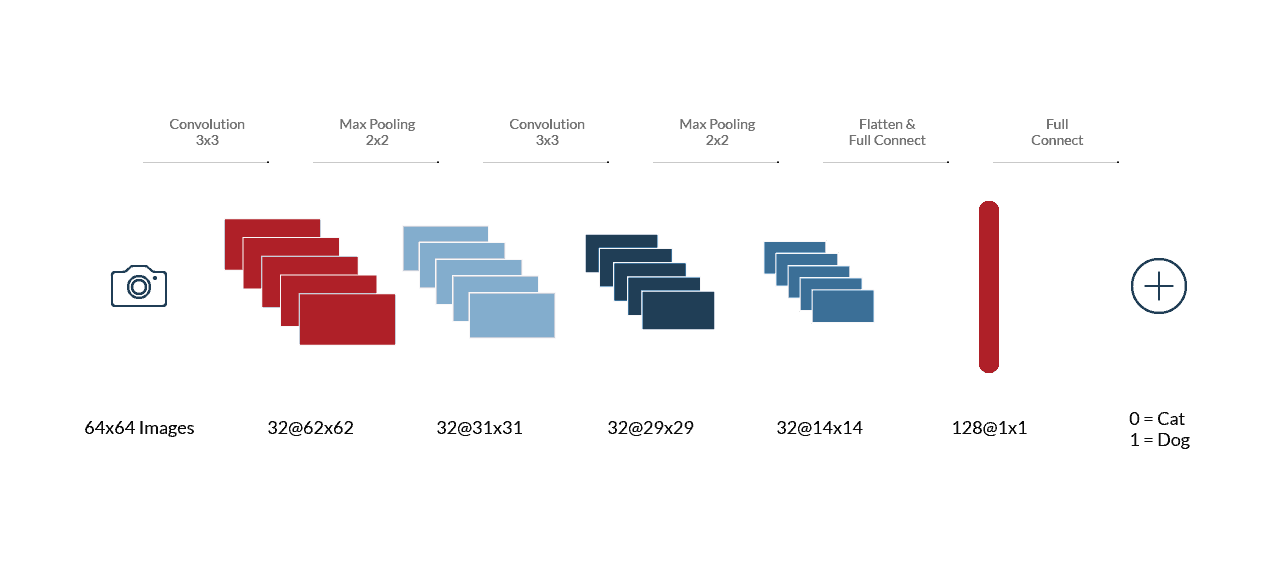
Figure 1: Original “Cat & Dog” Image Classification Convolutional Neural Network
The tutorial code is built using Python running on Keras. I chose a Keras example due to the simplicity of the API. I was able to get the system up and running relatively smoothly after installing Python and the necessary libraries (such as TensorFlow.) However, I quickly realized that running the code on a VirtualBox VM (Virtual Machine) on my workstation is painfully slow and inefficient. For example, it took ~90 minutes to process a single epoch (i.e., 8000 steps and 32 images per-step), and the default setting of 25 epochs required to train the network took more than a day and a half. I quickly realized that the sheer volume of time it takes, merely to view the effect of minor changes, would render this test useless and far too cumbersome.
I began to ponder how I could improve upon this process. After more research, I realized that a powerful GPU could be the solution I was after.
The opportunity to test such a GPU arose when I received a review unit of NVIDIA’s powerful new Tesla V100 GPU, which currently runs at a slightly eye-watering $9,000 price tag. After two weeks with the GPU, I learned many things: some expected and some entirely unexpected. I decided to write two blog posts to share what I learned with the hope that it can help others who are starting their journey into deep learning and are curious about what a GPU can do for them. What’s even more exciting, GPU Servers are available as a robust option for our Dedicated Server product lines.
In the first part of the blog, I focus on the training performance of the convolutional network, including observations and comparisons of the processing and training speeds with and without GPU. For example, I will showcase performance comparisons of the CIFAR-10 with the “cat and dog” image classifications deep convolution networks on the VirtualBox VM on my workstation, on a dedicated bare-metal server without GPU, and on a machine with the Tesla V100 GPU.
After tweaking the processing and training speeds of the network, I worked on improving the validation accuracy of the convolutional network. In the second part of the blog, I share the changes I made to Venkatesh’s model which enhances the validation accuracy of the CNN from ~80% to 94%.
This blog assumes that readers have foundational knowledge of neural and Deep Learning network terminology, such as validation accuracy, convolution layer, etc. Many of the contents will have added clarity if one has attempted Venkatesh’s or similar tutorials.
Observations on Performance & GPU Utilizations
Experiment with the workers and batch_size parameters
Whether the code is running on VirtualBox VM or a bare-metal CPU and with a GPU, changing these two parameters in the Keras code can make a significant impact on the training speeds. For example, with the VirtualBox VM, increasing the workers to 4 (default is 1) and batch_size to 64 (default is 32) improves the processing and training speed from 47 images/sec to 64 images/sec. With the GPU, the gain in training speed is roughly 3x after adjusting these parameters from the default values.
For a small network, GPU Computing is hardly utilized
I was quick to realize that maximizing the GPU for machine learning is a challenge.
With the original “cat and dog” image classification network, GPU utilization hovers between 0 to 10%. CPU utilization also hovers at roughly 10%. Experimenting with different parameters such as workers, batch_size, max_queue_size, and even storing the images on RAM Disk did not make a significant difference regarding GPU utilization and training speed. However, after additional research, I learned that the bottleneck is at the input pipeline (e.g., reading, decompress, and augmenting the images) before the training starts, which is handled through the CPU.
Nevertheless, the system with a GPU still produces 4x higher processing and training speeds than the bare metal hardware without a GPU (see training speed comparisons section below).
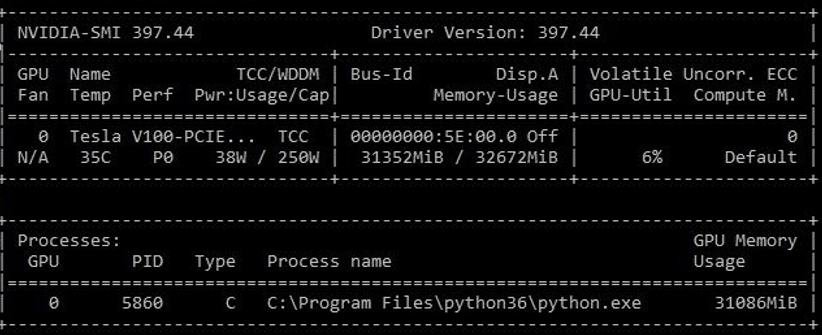
Figure 2: Low GPU Utilization on the original Cat & Dog CNN
The GPU for Machine Learning At Work
After increasing the complexity of the “cat and dog” network, which improved the validation accuracy from 80% to 94%, (e.g., increasing the depth of the network), the GPU utilization increased to about 50%. In the improved network (regarding accuracy), the image processing and training speed decreased by ~20% on the GPU, but it dropped by ~85% on the CPU. In this network, the processing and training speeds are about 23x faster on the GPU than the CPU.
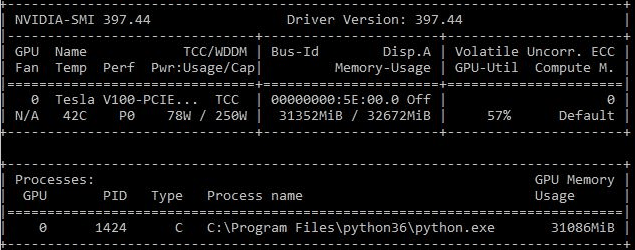
Figure 3: GPU Utilization on Improved Cat & Dog CNN
For experimental purpose, I created an (unnecessarily) deep network by adding 30+ convolutional layers. I was able to max out the GPU utilization to 100% (note the temperature and wattage from NVIDIA-SMI). Interestingly, the processing and training speeds stay about the same as the improved “cat and dog” network with the GPU. On the other hand, with the CPU, it can only process about three images/sec on this deep network, which is about 100 times slower than with a GPU.
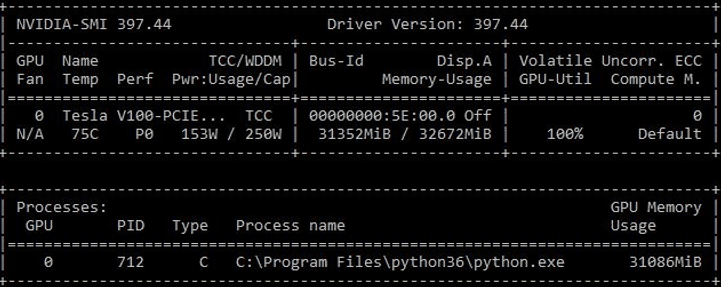
Figure 4: GPU Utilization on the Deep CNN
Training Speed Comparisons
CIFAR-10
The CIFAR-10 dataset is a commonly used image dataset for training GPU machine learning models. I ran the CIFAR-10 model with images downloaded from Github. The default batch_size is 128, and I experimented with different values with and without a GPU. On the Tesla V100 with batch_size 512, I was able to get around 15k to 17k examples/sec. GPU utilization was steady at ~45%.
This is a very respectable result, compared to the numbers published by Andriy Lazorenko. Using the same batch_size, with bare metal hardware running dual Intel Silver 4110 CPU (total 16 cores) and 128GB RAM, I was only able to get about 210 images/second, with the AVX2-compiled TensorFlow binaries. On the VirtualBox VM, I get about 90 images/second.
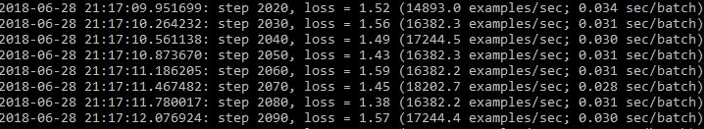
Figure 5: CIFAR-10 Output from Tesla V100
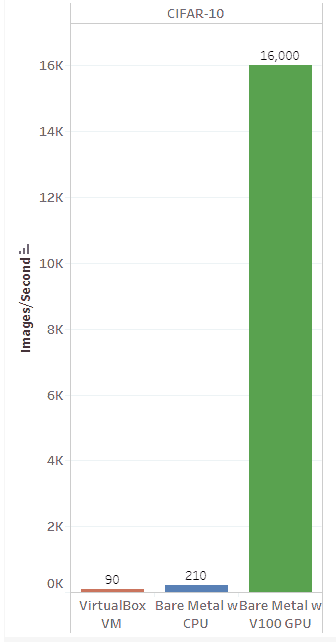
Figure 6: CIFAR-10 Training Speeds from VM, Bare Metal with & without GPU
Cat & Dog Image Classification Networks
The chart below shows the processing and training speeds of the different “cat and dog” networks on different systems. The parameters for each system (e.g., workers, batch_size) are tweaked from the default values to maximize performance. The performance improvement gains from using a powerful GPU, such as the V100, is more apparent as the networks become deeper and more complex.
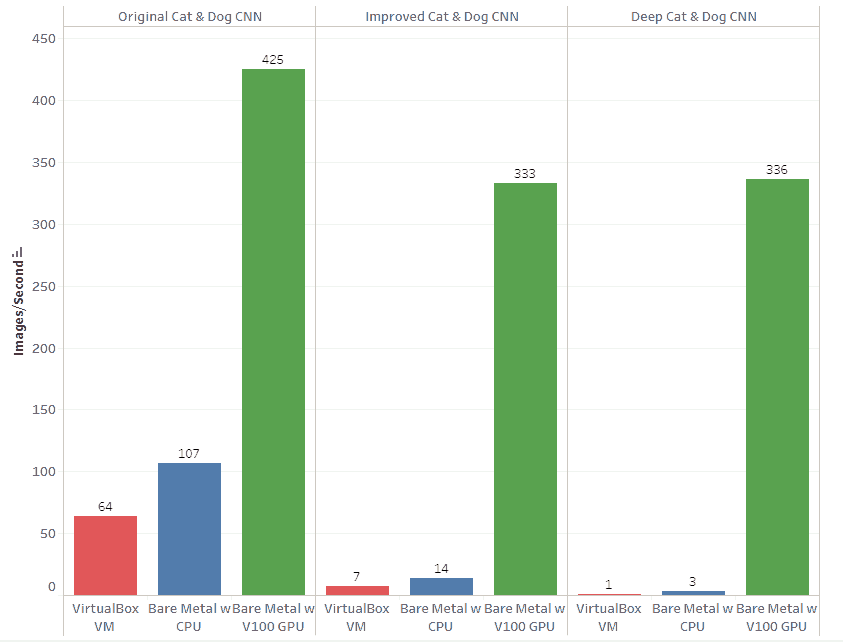
Figure 7: Training Speeds of CNNs from VMs, Bare Metal with & without GPU
Improving the Accuracy a Neural Network and Deep Learning
Previously, I compared the training performance of using CPU vs. GPU on many convolutional networks. I learned that the deeper and more complex the network is, the more performance benefits can be gained from using GPU.
In the second part of the blog, I describe the changes I made to the “Cat & Dog” Convolutional Neural Network (CNN) based on Venkatesh’s tutorial which improves the validation accuracy of the network from 80% to 94%. I also share the results of predictions from the trained network against random sets of images.
Figure 1: Original “Cat & Dog” Image Classification Convolutional Neural Network
Improvements to the Cat & Dog CNN
Add Convolutional and Max Pooling Layers
I added a pair of convolutional (64 filters) and max-pooling layers to the original network. The additional depth of the network improves validation accuracy from 80% to 84%. It does not result in any noticeable change in training speed.

Figure 2: Add a pair of Convolutional and Max Pool Layers
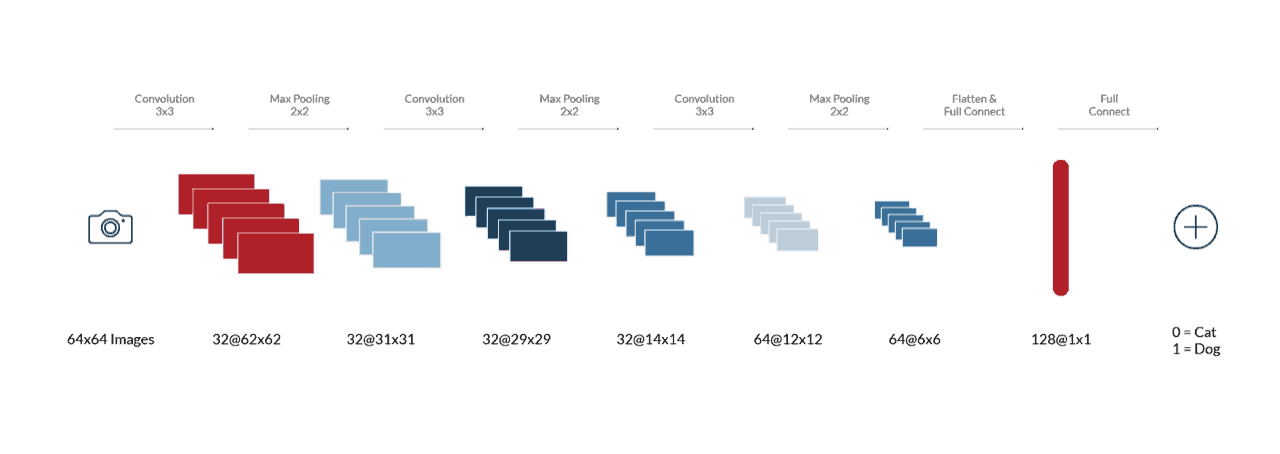
Figure 3: Cat & Dog CNN with additional convolutional & max pool layers
Add Dropout Layer
I added a dropout layer with a rate of 0.5, which randomly removes neurons from the trained network to prevent overfitting. The addition of the dropout layer improves the validation accuracy from 84% to 90%. It does not result in any noticeable change in training speed.

Data Augmentation
Data augmentation is a technique that generates variations of training images from the original images through a shift, rotation, zoom, shear, flip, etc. to train the model. Checkout Keras documentation of ImageDataGenerator class for more details. The original CNN already incorporates data augmentations, so this is not an improvement per se, but I am interested in understanding the effect of data augmentation on accuracy and training speed.

The following are examples of augmented images.

Figure 6: Examples of Augmented Images
To test the effect of data augmentation, I remove the shear, zoom and flip operations from the image data generator. The removal of data augmentation decreases the validation accuracy from 90% to 85%. It is worth noting that data augmentation does come with a performance overhead. Without data augmentation, the training performance on the GPU increases from 425 images/sec to 533 images/sec.
Increase the Target Image Resolutions
The original CNN resizes all images to 64×64 before training the model. I increased the target resolutions to 128×128 and added another pair of convolutional and max pool layers to the network to capture more details of the images. I also increased the number of filters to 64 on all layers. The new CNN with higher target image resolutions and more layers improves the validation accuracy from 90% to 94%. It also comes with performance overhead which decreases the training performance on the GPU from 425 images/sec to 333 images/sec.
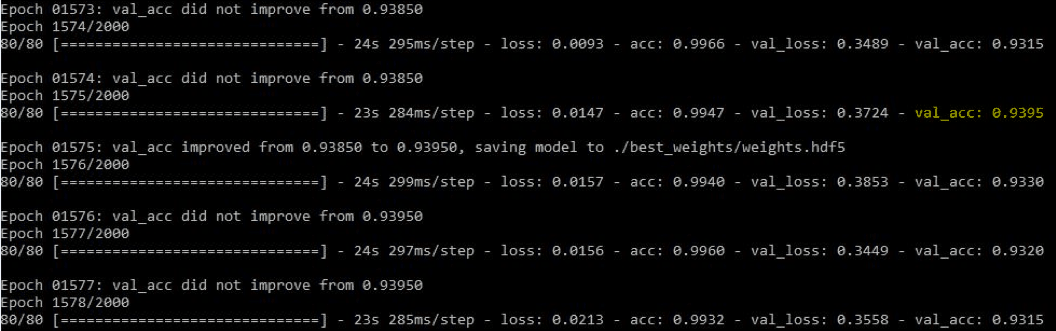
Figure 7: Validation Accuracy of 94%
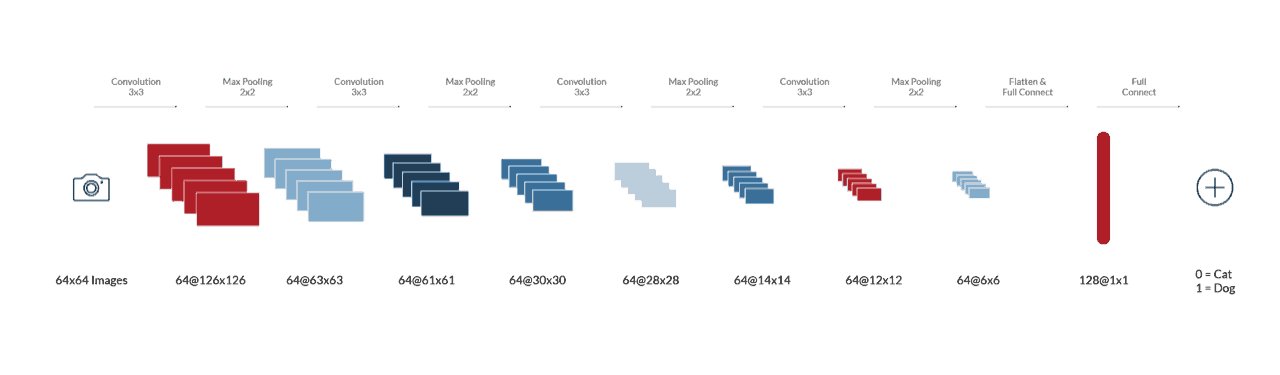
Figure 8: Improved Cat & Dog CNN
Predictions
Now, it’s the fun part, which is to use the trained model for predicting cat or dog images.
Errors in the Original CNN Code
I want to point out that the prediction code from Venkatesh’s tutorial is missing a critical line of code.

Figure 9: Original Prediction Example
Using this code will incorrectly tilt the prediction toward “dog.” The reason is the model is trained by rescaling the RGB values from 0-to-255 to 0-to-1 range. For the model to predict correctly as trained, we must also rescale the input RGB values from 0-to-255 to 0-to-1 range. Without rescaling, the input pixel values are 255 larger than what’s expected by the model, which will incorrectly tilt the result higher toward 1 (i.e., dog).
Another observation is the result[0][0] can return 0.00000xxx for cat and 0.99999xxx for dog, instead of absolute 0 or 1. So, I also changed the check to “>0.5” rather than “==1”. The modified and corrected code is shown the figure below.
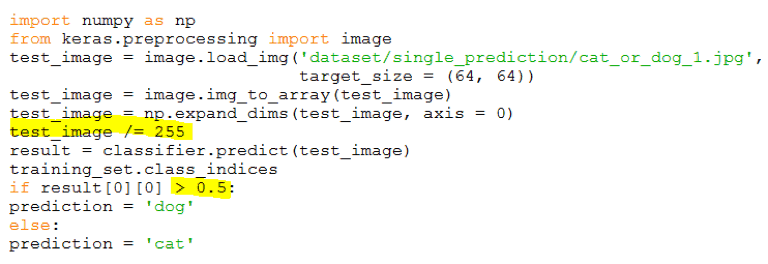
Figure 10: Corrected Prediction Code with Changes Highlighted
Predicting Images
So, how ‘intelligent’ is the CNN? How well can it predict cat and dog images, beyond those in the training and validation sets? Can it tell that Tom from “Tom & Jerry” is a cat? How about Pluto and Goofy from Disney? How about Cat Woman? How about wolves, tigers, and even human faces? Below are randomly downloaded images and the prediction results from the model.

Figure 11: Random images for the model to predict
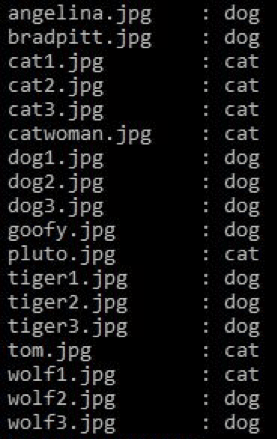
Figure 12: Results of prediction of random images
In Closing, GPU deep learning
Having powerful GPUs to train Deep Learning networks is highly beneficial, especially if one is serious about improving the accuracy of the model. Without the significant increase in training speeds from GPUs, which can be in the magnitude of 100x+, one would have to wait for arduous amounts of time to observe the outcomes when experimenting with different network architecture and parameters. That would essentially render the process impractical.
My two-week journey with the GPU loaner quickly came to an end. It was a fun and productive learning experience. Without the training speeds from the powerful NVidia V100 GPU card, all the changes, tweaks and experiments with different network architecture, parameters and techniques would not be possible within such a short period.




