Finding faults in a distributed system goes beyond the capability of standard application testing. Companies need smarter ways to test microservices continuously. One strategy that is gaining popularity is chaos engineering.
Using this proactive testing practice, an organization can look for and fix failures before they cause a costly outage. Read on to learn how chaos engineering improves the reliability of large-scale distributed systems.
What Is Chaos Engineering? Defined
Chaos engineering is a strategy for discovering vulnerabilities in a distributed system. This practice requires injecting failures and errors into software during production. Once you intentionally cause a bug, monitor the effects to see how the system responds to stress.
By “breaking things” on purpose, you discover new issues that could impact components and end-users. Address the identified weaknesses before they cause data loss or service impact.
Chaos engineering allows an admin to:
- Identify weak points in a system.
- See in real-time how a system responds to pressure.
- Prepare the team for real failures.
- Identify bugs that are yet to cause system-wide issues.
Netflix was the first organization to introduce chaos engineering. In 2010, the company released a tool called Chaos Monkey. With this tool, admins were able to cause failures in random places at random intervals. Such a testing approach made Netflix’s distributed cloud-based system much more resilient to faults.
Who Uses Chaos Engineering?
Many tech companies practice chaos engineering to improve the resilience of distributed systems. Netflix continues to pioneer the practice, but companies like Facebook, Google, Microsoft, and Amazon have similar testing models.
More traditional organizations have caught on to chaos testing too. For example, the National Australia Bank applied chaos to randomly shut down servers and build system resiliency.
The Need for Chaos Engineering
Peter Deutsch and his colleagues from Sun Microsystem listed eight false assumptions programmers commonly make about distributed systems:
- The network is reliable.
- There is zero latency.
- Bandwidth is infinite.
- The network is secure.
- Topology never changes.
- There is one admin.
- Transport cost is zero.
- The network is homogeneous.
These fallacies show the dynamics of a distributed application designed in a microservices architecture. This kind of system has many moving parts, and admins have little control over the cloud infrastructure.
Constant changes to the setup cause unexpected system behavior. It is impossible to predict these behaviors, but we can reproduce and test them with chaos engineering.
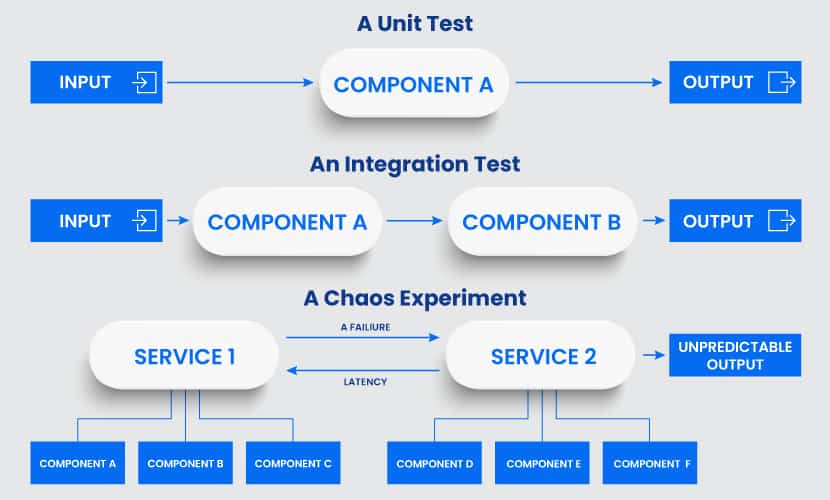
Difference Between Chaos Engineering and Failure Testing
A failure test examines a single condition and determines whether a property is true or false. Such a test breaks a system in a preconceived way. The results are usually binary, and they do not uncover new information about the application.
The goal of a chaos test is to generate new knowledge about the system. Broader scope and unpredictable outcomes enable you to learn about the system’s behaviors, properties, and performance. You open new avenues for exploration and see how you can improve the system.
While different, chaos and failure testing do have some overlap in concerns and tools used. You get the best results when you use both disciplines to test an application.
How Chaos Engineering Works
All testing in chaos engineering happens through so-called chaos experiments. Each experiment starts by injecting a specific fault into a system, such as latency, CPU failure, or a network black hole. Admins then observe and compare what they think will occur to what actually happens.
An experiment typically involves two groups of engineers. The first group controls the failure injection, and the second group deals with the effects.
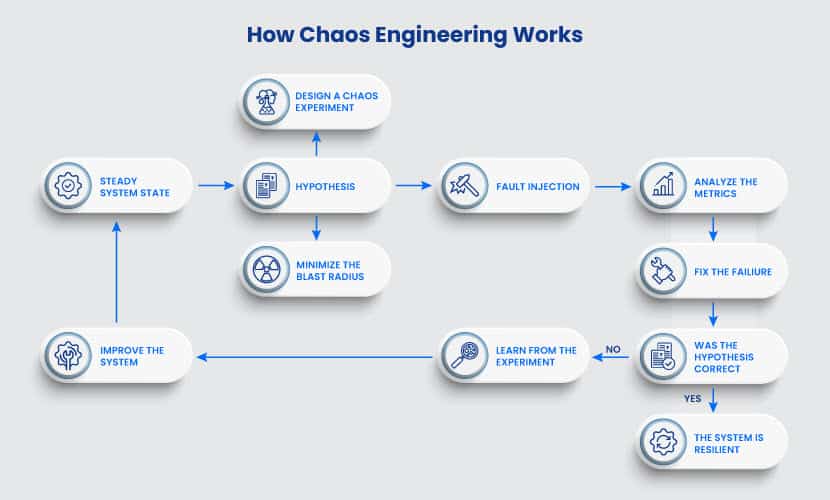
Here is a step-by-step flow of a chaos experiment:
Step 1: Creating a Hypothesis
Engineers analyze the system and choose what failure to cause. The core step of chaos engineering is to predict how the system will behave once it encounters a particular bug.
Engineers also need to determine critical metric thresholds before starting a test. Metrics typically come in two sets:
- Key metrics: These are the primary metrics of the experiment. For example, you can measure the impact on latency, requests per second, or system resources.
- Customer metrics: These are precautionary metrics that tell you if the test went too far. Examples of customer metrics are orders per minute, or stream starts per second. If a test begins impacting customer metrics, that is a sign for admins to stop experimenting.
In some tests, the two metrics can overlap.
Step 2: Fault Injection
Engineers add a specific failure to the system. Since there is no way to be sure how the application will behave, there is always a backup plan.
Most chaos engineering tools have a reverse option. That way, if something goes wrong, you can safely abort the test and return to a steady-state of the application.
Step 3: Measuring the Impact
Engineers monitor the system while the bug causes significant issues. Key metrics are the primary concern but always monitor the entire system.
If the test starts a simulated outage, the team looks for the best way to fix it.
Step 4: Verify (or Disprove) Your Hypothesis
A successful chaos test has one of two outcomes. You either verify the resilience of the system, or you find a problem you need to fix. Both are good outcomes.
Principles of Chaos Engineering
While the name may suggest otherwise, there is nothing random in chaos engineering.
This testing method follows strict principles, which include the following principles:
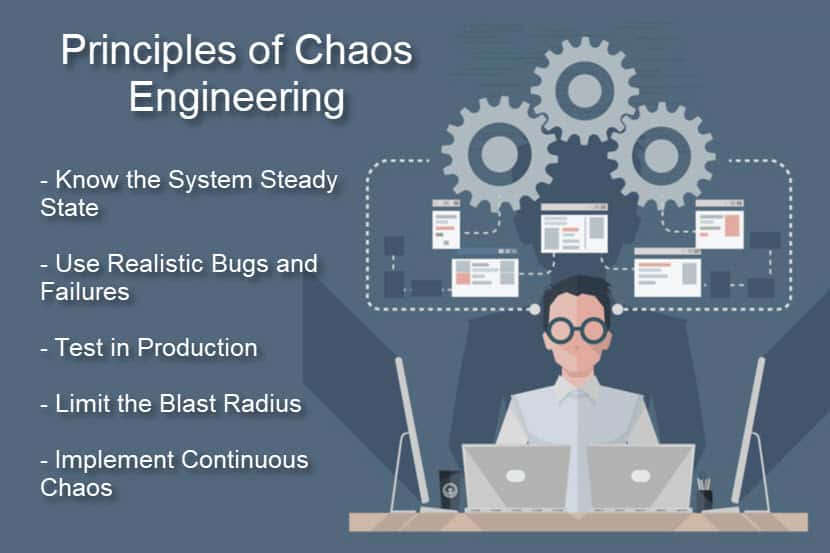
Know the Normal State of Your System
Define the steady-state of your system. The usual behavior of a system is a reference point for any chaos experiment. By understanding the system when it is healthy, you will better understand the impact of bugs and failures.
Inject Realistic Bugs and Failures
All experiments should reflect realistic and likely scenarios. When you inject a real-life failure, you get a good sense of what processes and technologies need an upgrade.
Test in Production
You can only see how outages affect the system if you apply the test to a production environment.
If your team has little to no experience with chaos testing, let them start experimenting in a development environment. Test the production environment once ready.
Control the Blast Radius
Always minimize the blast radius of a chaos test. As these tests happen in a production environment, there is a chance that the test could affect end-users.
Another standard precaution is to have a team ready for actual incident response, just in case.
Continuous Chaos
You can automate chaos experiments to the same level as your CI/CD pipeline. Constant chaos allows your team to improve both current and future systems continuously.
Benefits of Chaos Engineering
The benefits of chaos engineering span across several business fronts:
Business Benefits
Chaos engineering helps stop large losses in revenue by preventing lengthy outages. The practice also allows companies to scale quickly without losing the reliability of their services.
Technical Benefits
Insights from chaos experiments reduce incidents, but that is not where technical benefits end. The team gets an increased understanding of system modes and dependencies, allowing them to build a more robust system design.
A chaos test is also excellent on-call training for the engineering team.
Customer Benefits
Fewer outages mean less disruption for end-users. Improved service availability and durability are the two chief customer benefits of chaos engineering.
Chaos Engineering Tools
These are the most common chaos engineering tools:
- Chaos Monkey: This is the original tool created at Netflix. While it came out in 2010, Chaos Monkey still gets regular updates and is the go-to chaos testing tool.
- Gremlin: Gremlin helps clients set up and control chaos testing. The free version of the tool offers basic tests, such as turning off machines and simulating high CPU load.
- Chaos Toolkit: This open-source initiative makes tests easier with an open API and a standard JSON format.
- Pumba: Pumba is a chaos testing and network emulation tool for Docker.
- Litmus: A chaos engineering tool for stateful workloads on Kubernetes.
To keep up with new tools, bookmark the diagram created by the Chaos Engineering Slack Community. Besides the tools, the chart also keeps track of known engineers working with chaos tests.
Chaos Engineering Examples
There are no limits to chaos experiments. The type of tests you run depends on the architecture of your distributed system and business goals.
Here is a list of the most common chaos tests:
- Simulating the failure of a micro-component.
- Turning a virtual machine off to see how a dependency reacts.
- Simulating a high CPU load.
- Disconnecting the system from the data center.
- Injecting latency between services.
- Randomly causing functions to throw exceptions (also known as function-based chaos).
- Adding instructions to a program and allowing fault injection (also known as code insertion).
- Disrupting syncs between system clocks.
- Emulating I/O errors.
- Causing sudden spikes in traffic.
- Injecting byzantine failures.
Chaos Engineering and DevOps
Chaos engineering is a common practice within the DevOps culture. Such tests allow DevOps to thoroughly analyze applications while keeping up with the tempo of agile development.
DevOps teams commonly use chaos testing to define a functional baseline and tolerances for infrastructure. Tests also help create better policies and processes by clarifying both steady-state and chaotic outputs.
Some companies prefer to integrate chaos engineering into their software development life cycle. Integrated chaos allows companies to ensure the reliability of every new feature.
A Must for any Large-Scale Distributed System
Continuous examination of software is vital both for application security and functionality. By proactively examining a system, you can reduce the operational burden, increase system availability, and resilience.




