Introduction
There are several instances in which you may encounter duplicate rows in your MySQL database. This guide will walk you through the process of how to remove duplicate row values in MySQL.

Prerequisites
- A system with MySQL installed
- A MySQL root user account
- Access to a terminal window / command line (Ctrl-Alt-T, Search > Terminal)
Setting Up Test Database
If you already have a MySQL database to work on, skip ahead to the next section.
Otherwise, open a terminal window and type in the following:
mysql –u root –pWhen prompted, enter the root password for your MySQL installation. If you have a specific user account, use those credentials instead of root.
The system prompt should change to:
mysql>Note: If you aren’t able to connect to the MySQL server, you may get the message that access has been denied. Refer to our article on how to solve this MySQL error if you need assistance.
Create Test Database
You can create a new table in an existing database. To do so, find the appropriate database by listing all existing instances with:
SHOW DATABASES;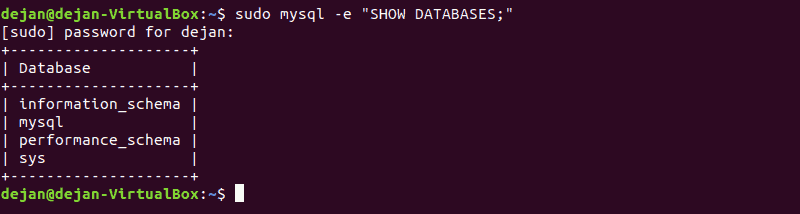
Alternatively, you can create a new database by entering the following command:
CREATE DATABASE IF NOT EXISTS testdata;
To start working in your new testdata database use:
USE testdata;Add Table and Data
Once in the database, add a table with the data below using the following command:
CREATE TABLE dates (
id INT PRIMARY KEY AUTO_INCREMENT,
day VARCHAR(2) NOT NULL,
month VARCHAR(10) NOT NULL,
year VARCHAR(4) NOT NULL
);
INSERT INTO dates (day,month,year)
VALUES (’29’,’January’,’2011’),
(’30’,’January’,’2011’),
(’30’,’January’,’2011’),
(’14’,’February,’2017’),
(’14’,’February,’2018’),
(‘23’,’March’,’2018’),
(‘23’,’March’,’2018’),
(‘23’,’March’,’2019’),
(‘29’,’October’,’2019’),
(‘29’,’November’,’2019’),
(‘12’,’November’,’2017’),
(‘17’,’August’,’2018’),
(‘05’,’June’,’2016’);Display the Contents of the Dates Table
To see a display of all the dates you entered, ordered by year, type:
SELECT * FROM dates ORDER BY year;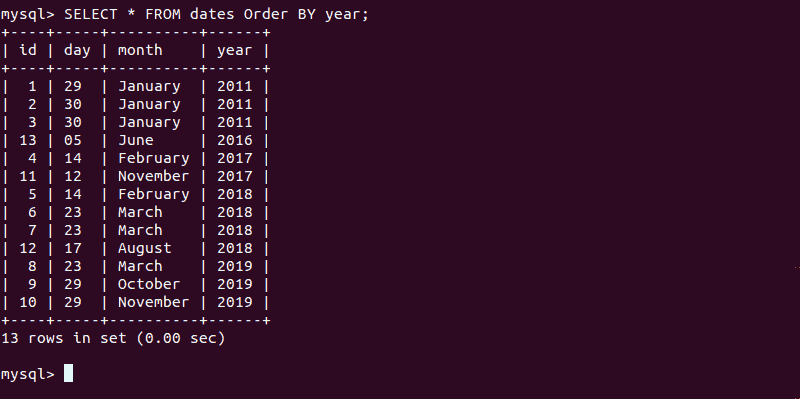
The output should show a list of dates in the appropriate order.
Display Duplicate Rows
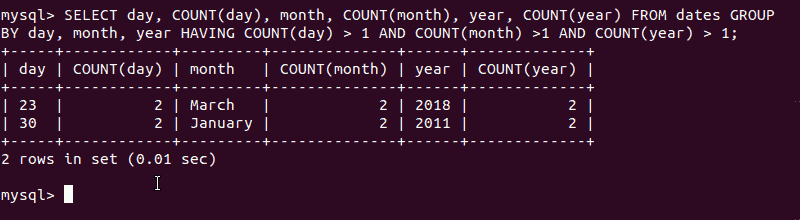
To find out whether there are duplicate rows in the test database, use the command:
SELECT
day, COUNT(day),
month, COUNT(month),
year, COUNT(year)
FROM
dates
GROUP BY
day,
month,
year
HAVING
COUNT(day) > 1
AND COUNT(month) > 1
AND COUNT(year) > 1;The system will display any values that are duplicates. In this case, you should see:
This format works to select multiple columns. If you have a column with a unique identifier, such as an email address on a contact list or a single date column, you can simply select from that one column.
Note: Learn about other ways to find duplicate rows in MySQL.
Removing Duplicate Rows
Prior to using any of the below-mentioned methods, remember you need to be working in an existing database. We will be using our sample database:
USE testdata;Option 1: Remove Duplicate Rows Using INNER JOIN
To delete duplicate rows in our test MySQL table, use MySQL JOINS and enter the following:
delete t1 FROM dates t1
INNER JOIN dates t2
WHERE
t1.id < t2.id AND
t1.day = t2.day AND
t1.month = t2.month AND
t1.year = t2.year;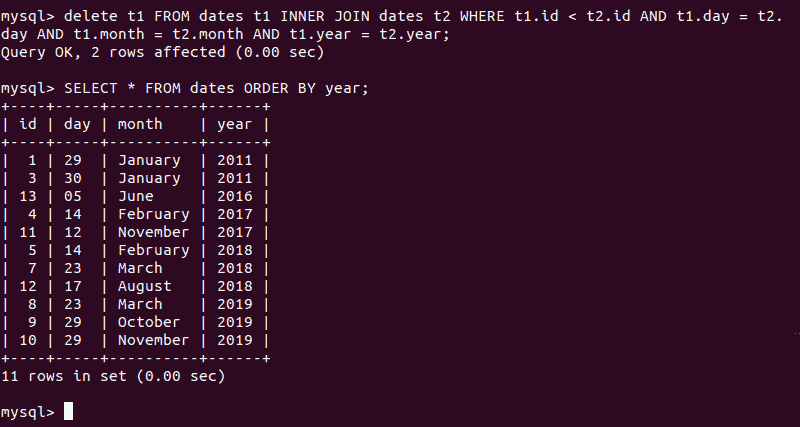
You may also use the command from Display Duplicate Rows to verify the deletion.
Note: If you have a unique column identifier, you can substitute it for the month, day, and year column identifiers, omitting the AND operators. This is designed to help you delete rows with multiple identical columns.
Option 2: Remove Duplicate Rows Using an Intermediate Table
You can create an intermediate table and use it to remove duplicate rows. This is done by transferring only the unique rows to the newly created table and deleting the original one (with the remaining duplicate rows).
To do so follow the instructions below.
1. Create an intermediate table that has the same structure as the source table and transfer the unique rows found in the source:
CREATE TABLE [copy_of_source] SELECT DISTINCT [columns] FROM [source_table];For instance, to create a copy of the structure of the sample table dates the command is:
CREATE TABLE copy_of_dates SELECT DISTINCT id, day, month, year FROM dates;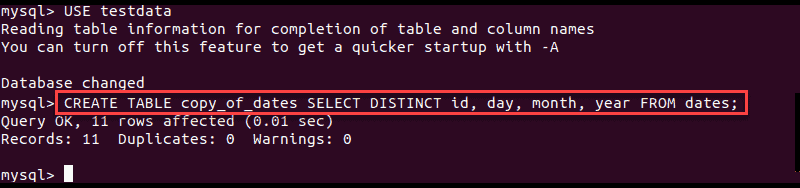
2. With that done, you can delete the source table with the drop command and rename the new one:
DROP TABLE [source_table];ALTER TABLE [copy_of_source] RENAME TO [source_table];For example:
DROP TABLE dates;ALTER TABLE copy_of_dates RENAME TO dates;
Option 3: Remove Duplicate Rows Using ROW_NUMBER()
Important: This method is only available for MySQL version 8.02 and later. Check MySQL version before attempting this method.
Another way to delete duplicate rows is with the ROW_NUMBER() function.
SELECT *. ROW_NUMBER () Over (PARTITION BY [column] ORDER BY [column]) as [row_number_name];Therefore, the command for our sample table would be:
SELECT *. ROW_NUMBER () Over (PARTITION BY id ORDER BY id) as row_number;The results include a row_number column. The data is partitioned by id and within each partition there are unique row numbers. Unique values are labeled with row number 1, while duplicates are 2, 3, and so on.
Therefore, to remove duplicate rows, you need to delete everything except the ones marked with 1. This is done by running a DELETE query with the row_number as the filter.
To delete duplicate rows run:
DELETE FROM [table_name] WHERE row_number > 1;In our example dates table, the command would be:
DELETE FROM dates WHERE row_number > 1;The output will tell you how many rows have been affected, that is, how many duplicate rows have been deleted.
You can verify there are no duplicate rows by running:
SELECT * FROM [table_name];For instance:
SELECT * FROM dates;Note: Consider using SQL query optimization tools as well to find the best way to execute a query and improve performance.
Conclusion
You should now be able to remove duplicate rows in MySQL and improve your database performance. Remember, new implementations of MySQL strict mode have limited the functionality of the required functions.
