Introduction
Resilient Distributed Datasets (RDDs) are the primary data structure in Spark. RDDs are reliable and memory-efficient when it comes to parallel processing. By storing and processing data in RDDs, Spark speeds up MapReduce processes.
This guide provides a comprehensive overview of Resilient Distributed Datasets.

What Is a Resilient Distributed Dataset?
A Resilient Distributed Dataset (RDD) is a low-level API and Spark's underlying data abstraction. An RDD is a static set of items distributed across clusters to allow parallel processing. The data structure stores any Python, Java, Scala, or user-created object.
Why Do We Need RDDs in Spark?
RDDs address MapReduce's shortcomings in data sharing. When reusing data for computations, MapReduce requires writing to external storage (HDFS, Cassandra, HBase, etc.). The read and write processes between jobs consume a significant amount of memory.
Furthermore, data sharing between tasks is slow due to replication, serialization, and increased disk usage.
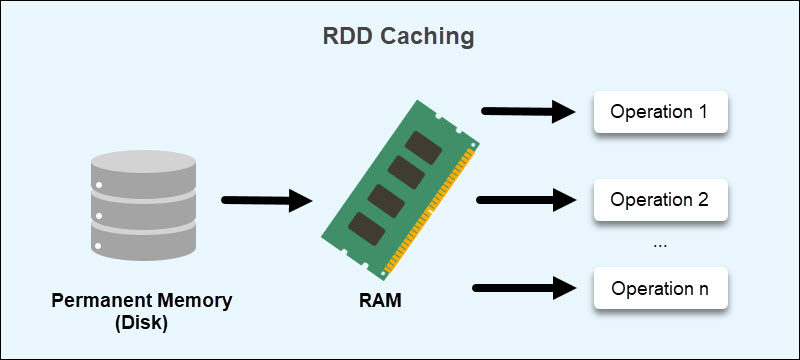
RDDs aim to reduce the usage of external storage systems by leveraging in-memory compute operation storage. This approach improves data exchange speeds between tasks by 10 to 100 times.
Speed is critical when working with large data volumes. Spark RDDs make it easier to train machine learning algorithms and handle large amounts of data for analytics.
How Does RDD Store Data?
An RDD stores data in read-only mode, making it immutable. Performing operations on existing RDDs creates new objects without manipulating existing data.
RDDs reside in RAM through a caching process. Data that does not fit is either recalculated to reduce the size or stored on a permanent storage. Caching allows retrieving data without reading from disk, reducing disk overhead.
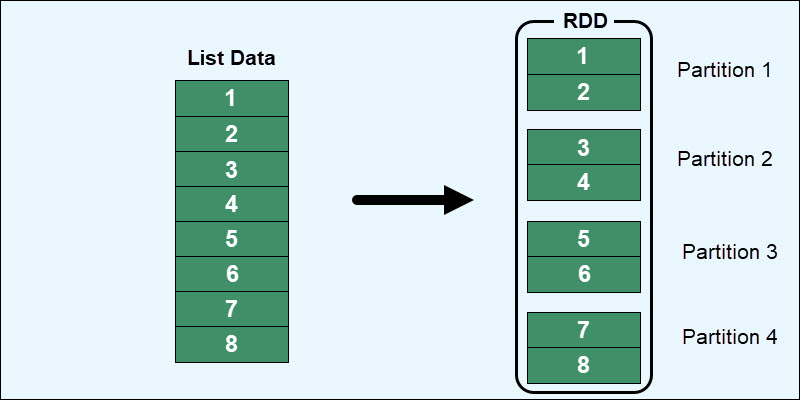
RDDs further distribute the data storage across multiple partitions. Partitioning allows data recovery in case a node fails and ensures the data is available at all times.
Spark's RDD uses a persistence optimization technique to save computation results. Two methods help achieve RDD persistence:
cache()persist()
These methods provide an interactive storage mechanism by choosing different storage levels. The cached memory is fault-tolerant, allowing the recreation of lost RDD partitions through the initial creation operations.
Spark RDD Features
The main features of a Spark RDD are:
- In-memory computation. Data calculation resides in memory for faster access and fewer I/O operations.
- Fault tolerance. The tracking of data creation helps recover or recreate lost data after a node failure.
- Immutability. RDDs are read-only. The existing data cannot change, and transformations on existing data generate new RDDs.
- Lazy evaluation. Data does not load immediately after definition - the data loads when applying an action to the data.
Spark RDD Operations
RDDs offer two operation types:
1. Transformations are operations on RDDs that result in RDD creation.
2. Actions are operations that do not result in RDD creation and provide some other value.
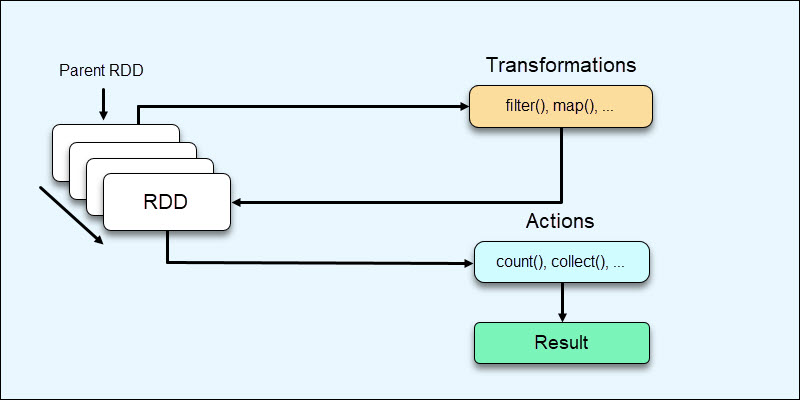
Transformations perform various operations and create new RDDs as a result. Actions come as a final step after completed modifications and return a non-RDD result (such as the total count) from the data stored in the Spark Driver.
Advantages and Disadvantages of RDDs
The advantages of using RDDs are:
- Data resilience. The self-recovery mechanism ensures data is never lost, regardless of whether a machine fails.
- Data consistency. Since RDDs do not change over time and are only available for reading, data consistency maintains throughout various operations.
- Performance speeds. Storing data in RAM whenever possible instead of on disk. However, RDDs maintain the possibility of on-disk storage to provide a massive performance and flexibility boost.
The disadvantages when working with Resilient Distributed Datasets include:
- No schematic view of data. RDDs have a hard time dealing with structured data. A better option for handling structured data is through the DataFrames and Datasets APIs, which fully integrate with RDDs in Spark.
- Garbage collection. Since RDDs are in-memory objects, they rely heavily on Java's memory management and serialization. This causes performance limitations as data grows.
- Overflow issues. When RDDs run out of RAM, the information resides on a disk, requiring additional RAM and disk space to overcome overflow issues.
- No automated optimization. An RDD does not have functions for automatic input optimization. While other Spark objects, such as DataFrames and Datasets, use the Catalyst optimizer, for RDDs, optimization happens manually.
Note: Leverage the power of Bare Metal Cloud and automate the provision of Spark clusters on BMC when you need more resources.
For the complete code, check out the Spark Demo on GitHub and ensure the efficiency of your data workloads.
Conclusion
Resilient Distributed Datasets are the core data structure in Spark. After reading this guide, you know how RDDs function and how they help optimize Spark's memory usage.
Next, check how to create a Spark DataFrame in various ways, including from a Resilient Distributed Dataset.
